Artificial Intelligence
https://simonwillison.net/2023/Dec/31/ai-in-2023/ https://www.cs.cornell.edu/~shmat/shmat_usenix21yam.pdf https://arxiv.org/pdf/2012.07805.pdf https://bair.berkeley.edu/blog/2020/12/20/lmmem/ https://www.technologyreview.com/2023/03/03/1069311/inside-story-oral-history-how-chatgpt-built-openai/ https://www.darkreading.com/risk/employees-feeding-sensitive-business-data-chatgpt-raising-security-fears https://www.gatesnotes.com/The-Age-of-AI-Has-Begun https://bit.kevinslin.com/p/leveraging-gpt-4-to-automate-the
fast.ai
Tldr
- 2 families of problems: classification and generation.
- 2 problem domains: sequential data (text) or two-dimensional data (image)
- 2 distinct phases:
- collecting data -> building a model
- using a model to generate / classify data
Problems solved by NN
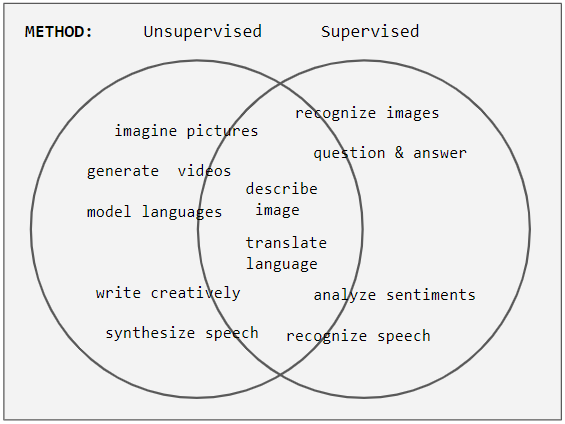
Classification
- discrimination / recognition: is it a X or a Y ? (spam filter, image recognition)
- clustering: grouping sets of similar objects together (fraud detection)
- anomaly detection detect outlier
- value attribution: attribute a score to an object (determine vip clients)
- prediction predict next object in set
Object class = the category for the object
Generation
- language modeling: given a token, give the probability distribution of the next token
- speech synthesis:
- image generation:
Overfitting: the NN doesn't generate anything new and spits back training data
A bit of both
- image description:
- language translation:
Basic pipeline (model training)
training data --->(data labeling)--->(training)---> trained model
Data labeling:
- finding, managing and labeling data
- some training methods big quantity of data
Training methods:
-
active learning: only a "seed input data" has to be labeled. Human intervention helps labeling the new unlabeled data (by asking questions or assigning values (for moderation tasks)) Human intervention == "mechanical turk" == micro tasks platforms / low cost manpower
-
supervised learning: ALL input data has to be labeled. Mostly used for discriminative tasks.
- unsupervised learning: input data doesn't need labeling. Mostly used for generative tasks.
Models:
Trained models can be downloaded (.bin)
llamacpp gpt4all huggingfacehub: model library
Langchain
1 2 | |
https://www.pinecone.io/learn/langchain-intro/ https://github.com/imartinez/privateGPT/blob/main/privateGPT.py
Neural networks (NN) types
| Type | Description | Usage | Links | Working examples |
|---|---|---|---|---|
| Perceptron | The first one (1957). Layer of neurons + activation function | classifier | medium.com |
Image
| Type | Description | Usage | Links | Working examples |
|---|---|---|---|---|
| Convolutional (CNN) | image | |||
| Generative Adversarial (GAN) | generator + discriminator. | image |
Text
| Type | Description | Usage | Links | Working examples |
|---|---|---|---|---|
| Recurrent (RNN) | text | |||
| Long Short Term Memory (LSTM) | text | github.com | Pythia | |
| Attention | text | |||
| Transformer | text | |||
| Large Language Model (LLM) | text | [openai.com]((https://community.openai.com/t/foundational-must-read-gpt-llm-papers/197003/2) | ChatGPT, Google Bard |
Vocabulary
Used since the perceptron days to the current LLMs.
- Neurone: fonction qui prend un input et output une valeur d'activation entre 0 et 1
- Weights
- Sigmoid: fonction qui prend n'importe quoi et le squash entre 0 et 1 (utile pour déterminer la valeur d'activation du neurone du layer suivant)
- ReLu (Rectified Linear Unit): autre type de fonction pls simple et plus rapide
- Bias: ajoute un threshold d'activation
- Learning: trouver les bias et weights "corrects" en minimisant la fonction de cost.
- Trouver un minimum: la technique de trouver la pente (gradient) permet de trouver un minimum local. Il faut répéter cette méthode pour chaque neurone (le signe du gradient renseigne sur la nécessité d'augmenter/diminuer le poids et la valeur renseigne sur la magnitude du changement nécessaire pour atteindre le minimum)
- Représentation = matrices
- Training data
- Testing data: doit evidemment être différente de la training data
- Loss/cost: distance entre le training data set et l'output de l'AI (lower the better)
- Training = minimizing the loss function ovr each training
- Epoch
- Encoder and Decoder
https://github.com/mnielsen/neural-networks-and-deep-learning
Using a model
See Tensorflow
Word vectors
SpaCy: natural language processor = permet de tokenizer un texte et de classifier les tokens. Peut-être utilisé pour préparer un texte d'apprentissage ML. Word2vec https://gist.github.com/aparrish/5732d2f50166930113fb138fe9f09554
Libraries
High level
- Keras: supervised learning
Low level (backend engines)
- Torch: LuaJIT
- pytorch: wrapper de Torch en Python
- tensorflow: low level API
- MXNet: apache, open source
- CNTK: microsoft, open source
- Theano
Data types
Training data Test data Validation Data
- Tensor: modèle de représentation de données utilisé par Tensorflow (matrice 3D)
Communauté
Kaggle
Compétitions (with prizes), public datasets
Predicting HOTS games: https://www.youtube.com/watch?v=wjOEHvzv15s
OpenAI
Initiative open source, soutenue par Elon Musk, AWS.
- Baselines: algorithmes de renforcement
- Gym: benchmark
- Models are opaque - don't know how they are trained etc
DeepMind
Société basé au Royaume-Uni, CEO Demis Hassabis.
- 2014: acquisition par Google
- 2016: AlphaGo bat le champion de Go (basé sur une bdd de moves)
- 2017: AlphaZero, une version plus puissante/généraliste (shogi, échecs, go) + s'entraine only par self-play
- 2018: AlphaFold, prédiction molécules 3D (recherche Parkinson/Alzeihmer)
- 2019: AlphaStar: starcraft
Loi de Moore pour AI
source: openai.com
La puissance de calcule nécessaire à TRAIN une AI double tous les 3.5 mois. (la loi de Moore c'était tous les 18 mois)
AlphaGo Zero est souvent présentée comme une AI qui consomme peu, mais c'est uniquement pendant sa phase de run. La phase de train est la plus massive.